본 내용은 '김기현의 자연어 처리 딥러닝 캠프(한빛미디어)'를 정리한 내용입니다.
"문장을 확률로(언어 모델) 나타내 자연어를 생성하거나 여러가지 자연어 문제의 성능을 올릴 수 있다."
* 학습 목표 : 언어 모델이란?(정의, 평가방법, 활용)
1. 언어 모델이란?
1) 언어 모델(LM Language Model) : 문장의 확률을 나타내는 모델
- 단어의 나열(문장)에 확률을 부여하여, 그 문장이 일어날 가능성이 어느정도인지
(얼마나 자연스러운 문장인지) 확률로 평가하는 것
ex> You say goodbye : 0.092
You say good die : 0.0000000032
2) 문장의 확률 표현

- 위 식에서, 문장의 확률(좌항)은 이전 단어들의 사후 확률(우항)으로부터 계산할 수 있음
- 문장 이 길어지면 곱셈이 많아지며 확률이 매우 낮아져 정확한 계산이나 표현이 어려워지고 연산속도도 느려짐
이 때, 로그를 취해 덧셈으로 바꾸면 더 나은 조건을 취할 수 있음 (↓)

- 이 때, 이전 단어들의 사후 확률(첫번째 식 우항)은 아래식과 같이 단어 조합의 출현 빈도를 구해 추정할 수 있음

3) 한국어의 언어 모델 표현은 훨씬 어려움
(1) 교착어(접사/조사에 따라 의미/역할이 달라짐)이기 때문에 희소성 증가
(ex> 과학+자, 과학+실, 학교+에, 학교+를)
(2) 단어의 어순이 중요하지 않아 단어 간의 확률 계산에 불리
(ex> 나는 학교에 간다. 버스를 타고.
나는 버스를 타고 학교에 간다.
버스를 타고 나는 학교에 간다.
위 경우, '타고' 뒤에 '., 학교에, 나는' 3가지 경우가 올 수 있어 확률이 퍼지는 현상이 나타남)
2. n-gram
- 전체 단어 조합이 아니라 일부 단어 조합의 출현 빈도만 계산하여 확률을 추정하는 방법(희소성 해결)
(전체 단어 조합의 경우, 아예 출현 빈도를 구할 수 없거나, 확률이 너무 낮아져버림)
1) n-gram과 마르코프 가정
- 마르코프 가정 : 특정 시점의 상태 확률은 그 직전 상태에만 의존한다.
즉, 앞서 출현한 모든 단어를 볼 필요없이 앞의 k개만 보고 다음 단어의 출현 확률을 구하는 것
- k = 0 : unigram
k = 1 : bi-gram
k = 2 : tri-gram
- 훈련 코퍼스의 양이 적당하다면 대부분 3-gram을 사용
=> 문장 전체의 확률에 대해(훈련 코퍼스 내에 해당 문장이 존재한 적이 없어도) 마르코프 가정을 통해
해당 문장의 확률을 근사할 수 있게됨(훈련 코퍼스에서 보지 못한 문장도 확률 추정 가능)
2) 언어 모델을 일반화하는 방법
- 일반화 : 좋은 머신러닝은 훈련 데이터에서 보지 못한 샘플의 예측 능력(일반화 능력)에 의해 좌우됨
(1) 스무딩과 디스카운팅
- 문제 : 출현 빈도를 확률값으로 추정할 경우, 훈련 코퍼스에 출현하지 않는 단어 시퀀스에 대한 대처 능력이 떨어짐
- 해결책 : 출현하지 않았다고 확률을 0으로 추정하는 것이 아니라 빈도값이나 확률값을 다듬어 줘야 함
→ 스무딩, 디스카운팅 : 들쭉날쭉한 출현 횟수 값을 부드럽게 해주는 것
- 방법 : 모든 단어 시퀀스 출현 빈도에 1(혹은 상수값)을 더하기
(2) Kneser-Ney 디스카운팅
- 해결책 : 다양한 단어 뒤에 나타나는 단어일수록 훈련 코퍼스에서 보지 못한 단어 시퀀스로 나타날 가능성이 높다!
(ex> 딥러닝 책의 경우, learning과 book이라는 단어 중에서
machine, deep, supervised, generative... : learning
slim, favorite, fancy, expensive, chaep... : book
book이 훈련 코퍼스에서 보지 못한 단어 시퀀스에서 나타날 확률이 더 높다고 가정하고 점수를 더 주는 것)
(3) 인터폴레이션
- 인터폴레이션 : 두 개의 다른 언어 모델을 선형적으로 일정 비율 섞어주는 것
- 특정 영역에 특화된 언어 모델 구축 시 유용한데, 일반 영역의 코퍼스를 통해 구축한 언어 모델을 특정 영역의
작은 코퍼스로 만든 언어 모델과 섞어주어 특정 영역에 특화된 언어 모델을 강화 할 수 있음. 상호보완적 역할
(4) 백오프
- n-gram의 확률을 n보다 더 작은 시퀀스에 대해 확률을 구해 인터폴레이션 하는 것
(ex> 3-gram 확률은 2-gram, 1-gram 확률을 인터폴레이션)
- n보다 더 작은 시퀀스를 활용해 더 높은 스무딩, 일반화 효과 가능
4) 결론
n-gram 방식은 출현 빈도를 통해 확률을 근사해 매우 쉽고 간편함. 하지만 단점도 명확해 훈련 코퍼스에 등장하지 않은 단어 시퀀스는 확률을 정확하게 알 수 없음. 이를 해결하기 위해 마르코프 가정을 통해 단어 조합에 필요한 조건을 간소화하고, 스무딩과 백오프 방식을 통해 남은 단점을 보완함. 워낙 간단하고 명확해 성공적으로 음성 인식이나 기계번역에 정착해 십 수 년 동안 쓰여져 옴. 하지만 여전히 근본적인 해결책은 아니라 한계가 있음. 딥러닝 시대인 지금도 n-gram은 여전히 강력하게 활용됨. 문장을 생성하는 문제가 아니라 주어진 문장의 유창성을 채점하는 경우, 굳이 복잡한 신경망없이도 n-gram 방식으로 좋은 성능을 낼 수 있음
3. 언어 모델의 평가 방법
- 좋은 언어 모델이란?
실제 우리가 쓰는 언어와 최대한 비슷하게 확률 분포를 근사하는 모델
많이 쓰는 문장은 확률 높게, 적게 쓰는 문장은 확률 적게
1) 퍼플렉서티(PPL : perplexity)
- 문장의 길이를 반영하여 확률값을 정규화한 값
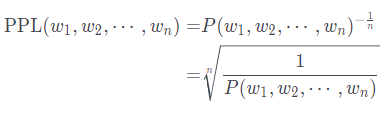
- 확률값이 높을수록 PPL은 작아짐, PPL 수치가 낮을 수록 좋음
- 의미 : 뻗어나갈 수 있는 경우의 수
(ex> ppl 30인 경우, 평균 30개의 후보 단어 중에 다음 단어를 선택할 수 있다는 이야기)
- 엔트로피와 PPL의 관계는 아래식과 같음.
MLE를 통해 파라미터를 학습할 때, 교차 엔트로피를 통해 얻은 손실값에 exp를 취하여 PPL을 얻을 수 있다는 것
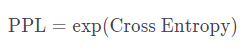
4. NNLM
- n-gram기반 언어 모델은 간편하지만, 단어간 유사도를 모르기 때문에, 훈련 데이터에서 못 본 단어 조합에는 취약함
- 신경망은 단어 임베딩을 사용하여 단어를 차원 축소해 단어간의 유사도를 알 수 잇고, 훈련 코퍼스에서 보지 못했던 단어의 조합을 만나더라도 비슷한 훈련 데이터로부터 배운 것과 유사하게 대처할 수 있음. 즉, 희소성 해소를 통해 좋은 일반화 성능을 가질 수 있음
5. 언어 모델의 활용
- 언어 모델을 단독으로 사용하는 경우는 거의 없지만, 자연어 생성의 가장 기본이 되는 모델이기 때문에 중요함
- 음성인식 정확도 상승(음성 인식한 후 여러 후보들 중에서 선정 가능), 자연스러운 기계번역 문장 생성, 광학문자인식 시 더 높은 성능 획득 가능
- 기타 자연어 생성 문제 : 뉴스 기사 쓰기, 뉴스 기사 요약해 제목 짓기, 사용자 응답 따라 대답 생성하는 챗봇
- 검색엔진의 드롭다운
6. 정리
- 주어진 문장을 확률적으로 모델링하는 방법인 언어모델의 필요성은 딥러닝 이전부터 꾸준히 있었음. n-gram 방법론을 통해 많은 곳에서 활용되어왔지만 단어를 불연속적으로 취급하다보니 희소성 문제를 해결하지 못해 일반화 능력에서 어려움이 있었음. 마르코프 가정, 스무딩 등을 통해 단점을 보완하고자 했지만 완벽한 해결책이 될 수는 없음
- 신경망을 통해 언어모델링을 수행하면 일반화 문제는 해결됨. 신경망은 비선형적 차원 축소에 매우 뛰어난 성능을 가지므로, 희소한 단어들의 조합에 대해서도 효과적으로 차원 축소하여 기존 훈련 데이터 내의 다른 단어 조합에 대한 유사도 비교 등을 훌륭하게 수행함. 따라서 추론 수행 과정에서 처음 보는 시퀀스의 데이터가 주어져도 기존에 자신이 배운 것을 기반으로 훌륭하게 예측함
'데이터 > NLP' 카테고리의 다른 글
| 14. NMT 시스템 구축[김기현의 자연어 처리 딥러닝 캠프] (0) | 2020.09.06 |
|---|---|
| 11. 신경망 기계번역 심화 주제[김기현의 자연어 처리 딥러닝 캠프] (0) | 2020.07.24 |
| 6. 단어 임베딩[김기현의 자연어 처리 딥러닝 캠프] (0) | 2020.05.31 |