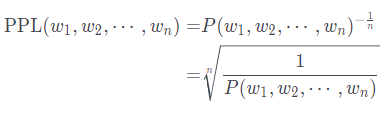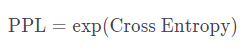본 내용은 '김기현의 자연어 처리 딥러닝 캠프(한빛미디어)'를 정리한 내용입니다.
"이제까지 배운 자연어 처리 알고리즘은 실제 필드에 어떻게 적용될까?"
* 학습 목표 : NMT 시스템 구축 절차 및 구글, 에든버러 대학, MS, 네이버의 NMT
1. 기계번역 시스템 구축 절차
ㅇ 기계번역뿐만 아니라 기본적인 자연어 처리 문제 전반에 적용 가능

1) 코퍼스 수집 : WMT(기계번역 경진대회), 뉴스 기사, 드라마/영화 자막, 위키피디아 등
2) 정제 : 말뭉치 문장 단위 정렬부터 특수 문자 노이즈 제거 등
3) 분절 : 언어별 형태소 분석기(POS tagger)/분절기(tokenizer, segmenter)를 사용해 띄어쓰기/대소문자 정제 등
- 한국어 형태소 분석기(Mecab, KoNLPy)
- 띄어쓰기 후 추가 분절 : Subword, WordPiece 같은 공개툴을 통해 BPE(Byte Pair Encoding)
4) 미니배치 구성 : 미니배치 내 문장 길이 통일(ex> 5단어 문장끼리, 70단어 문장끼리 미니배치 구성)
5) 훈련 : 준비된 데이터셋으로 seq2seq 모델 훈련
6) 추론 : 성능 평가(evaluation)를 위한 추론 수행, 테스트셋 난이도가 적절해야 함
7) 분절복원(detokenization) : 추론 후에도 실제 사람이 사용하는 문장과는 다름. 실제 사용되는 문장 형태로 반환
8) 성능평가 : 얻어진 문장 정량 평가(기계번역-BLEU), 정성 평가, 두 지표 모두 개선되었을 시 서비스 적용 가능
ㅇ 서비스 과정
1) API 호출/사용자 입력 : 대부분 서비스별 API 서버를 만들어 실제 프론트엔드에서 API 호출을 받아 프로세스 시작
2) 분절 : 실제 모델에 훈련된 데이터셋과 동일한 형태로 분절. 훈련과 똑같은 툴과 모델을 사용해야 함
3) 추론 : 속도가 중요. 많은 수의 문장일 경우 병렬 연산을 통한 처리 속도 증가 등이 필요
4) 분절 복원 : 사람이 읽을 수 있는 형태로 다시 복원
5) API 결과 반환/사용자에 결과 반환 : 최종 결과물을 API 서버에서 반환
2. 구글의 NMT
ㅇ seq2seq 기반 모델
ㅇ 방대한 데이터셋에 맞는 깊은 모델(8 Layer LSTM) 구성(+레지듀얼 커넥션 활용)
- 보통 LSTM 계층이 4개 이상이 되면 모델이 깊어짐에 따라 성능 효율이 저하됨.
이 때, 레지듀얼 커넥션을 통해 기울기 소실 문제를 해결할 수 있고 더 깊은 신경망을 효율적으로 훈련할 수 있음

ㅇ 첫번째 층에 양방향 LSTM 적용 : 성능의 큰 하락 없이 훈련 및 추론 속도 개선

ㅇ BPE 적용
ㅇ 강화학습을 통해 기계번역 성능 향상 : 기존 MLE + RL 선형결합으로 최종적인 목적 함수 설정
- MLE는 BLEU 평가 지표와 부합하지 않아 조금 다른 목적의 함수를 도입(RL)


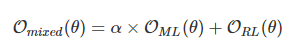
ㅇ 양자화(Quantization) : 실제 서비스에 적용할 때는 양자화된 모델을 사용해 추론 시간을 줄여줌
- 계산량 줄여 자원의 효율적 사용, 응답시간 감소, 부가적 regularization 효과 등

ㅇ 디코더에 길이 페널티, 커버리지 페널티 사용
ㅇ SGD + Adam 같이 사용했을 때 더 좋은 성능을 발휘
- 첫번째 epoch은 아담을 사용해 낮은 손실값까지 빠르게 학습 후, 두번째부터 SGD 사용해 최적화

ㅇ 결과 : 통계기반방식과 비교해 엄청난 성능 개선.
구글은 이 논문을 통해 SMT 시대의 종말을 선언하고 자연어 처리분야에서 딥러닝 시대를 본격적으로 선포
3. 에든버러 대학교 NMT
- 조금 더 현실적인 스케일의 NMT
ㅇ 서브워드 분절 : BPE 방식을 통한 분절 방식 처음 제안
ㅇ seq2seq 기반 모델. GRU 사용. 레지듀얼 커넥션으로 깊은 RNN(인코더 4, 디코더 8 layer). Adam만 사용
ㅇ 단방향 코퍼스 활용 : back-translation 처음 제안. 합성 병렬 코퍼스를 구성해 훈련 데이터셋에 추가
ㅇ 앙상블
4. MS NMT
- 이미 일정 수준 이상 발전한 기술 기반 위에서 성능을 더욱 견고히 하는 방법에 대한 설명
- 주로 중국어-영어 간 기계번역, 뉴스 도메인 번역에서 사람과 비슷한 성능에 도달
(단, 다른 도메인과 언어쌍에는 부족)
ㅇ 트랜스포머 구조를 사용한 seq2seq 구현
- 트랜스포머를 메이저 상용시스템에 성공적으로 적용한 사례
ㅇ 듀얼리티 활용 : DSL(듀얼 지도학습)+DUL(듀얼 비지도학습, 단방향 코퍼스 활용 성능 극대화) 모두 사용
ㅇ 딜리버레이션 네트워크 활용 : 소스문장에서 번여 초안을 얻고, 초안으로부터 최종 타깃 문장을 번역

'데이터 > NLP' 카테고리의 다른 글
| 11. 신경망 기계번역 심화 주제[김기현의 자연어 처리 딥러닝 캠프] (0) | 2020.07.24 |
|---|---|
| 9. 언어 모델링[김기현의 자연어 처리 딥러닝 캠프] (0) | 2020.06.28 |
| 6. 단어 임베딩[김기현의 자연어 처리 딥러닝 캠프] (0) | 2020.05.31 |